Predicting Healthcare Claim Denials with Natural Language Processing Techniques

US healthcare billing is fundamentally broken. The current system—rife with avoidable denials, appeals, overpayments and underpayments—is painful and expensive for everyone. Anomaly is tackling this issue and streamlining healthcare billing for payers, providers, and patients. We are dedicated to ensuring that the right amount is paid the first time—reducing healthcare costs and complexity for everyone. We are working with leading healthcare companies and leveraging advanced technology to realize this vision.
Claims are the language of healthcare. In this blog post we’ll talk about claims data and how advanced techniques from the domain of Natural Language Processing (NLP) can be applied to the challenge of predicting claim denials.
A claim denial results when the insurance company receives and processes a claim from the provider and deems it unpayable. A denial can delay payment to the provider, impacting their ability to pay for staff and supplies. In some cases the patient may even be “balance-billed” for the denied service.
Claim denials can come in all sorts of shapes and sizes. Thus, training a prediction model requires analysis of massive datasets that cover a full gambit of possible denials. For every given claim, its history can be pieced together: was the claim denied? Was that denial appealed? Was the denial overturned and the claim paid? Furthermore, from the claims, we can determine the reason for the denial. Perhaps the patient’s diagnosis didn't match the executed medical procedure. Or maybe some critical bit of information was left off the claim. Or perhaps a certain surgery was erroneously billed twice. Converting recorded claim denials into a labeled dataset is relatively straightforward. However, the transformation of raw claims into model features requires forethought.
In order to understand how to best feed raw claims into a model, we need to first understand the basic structure of a claim. Essentially, a claim is a record of sequential interactions between a patient and a healthcare professional, or “provider.” Suppose a patient attends a regular checkup appointment. The doctor takes a blood draw and then sends the sampled blood off for analysis. Afterwards the doctor performs a simple surgical procedure to have an unwieldy mole removed from the patient’s shoulder. That mole is also sent off for lab analysis. Each of these sequentially recorded procedures is recorded as a distinct procedure code within the claim. Additionally, every patient diagnosis is recorded as a diagnosis code. This sequence of procedures and diagnoses captures the narrative of the patient’s health history. In many ways, these sequences of discrete codes that make up claims are not that different from the sequences of words that make up a sentence or a paragraph. Thus, claim analysis is very much analogous to text analytics. Feature extraction techniques from Natural Language Processing (NLP) can therefore be applied to our claim denial prediction problem.
Many NLP modeling techniques are also applicable to claims data. Consider for example, a simple bag-of-words model in which a sentence is converted to a vector of word-counts. This approach easily extends to vectorizing the procedures within the claims. Once we compute the procedure-count vector, we can apply more nuanced modifications, such as term frequency-inverse document frequency (TFIDF) scoring of vector elements. In NLP, we commonly multiply document word-counts by the log of the inverse document frequencies in order to dampen the impact of very common words within the documents. Similarly, certain very common procedures (such as blood draws) can add unnecessary noise to vector models. Multiplying the procedure counts by the analogous “log of inverse claim frequencies” will help eliminate that noise. After vectorization, the resulting feature matrix can easily be inputted into any model.
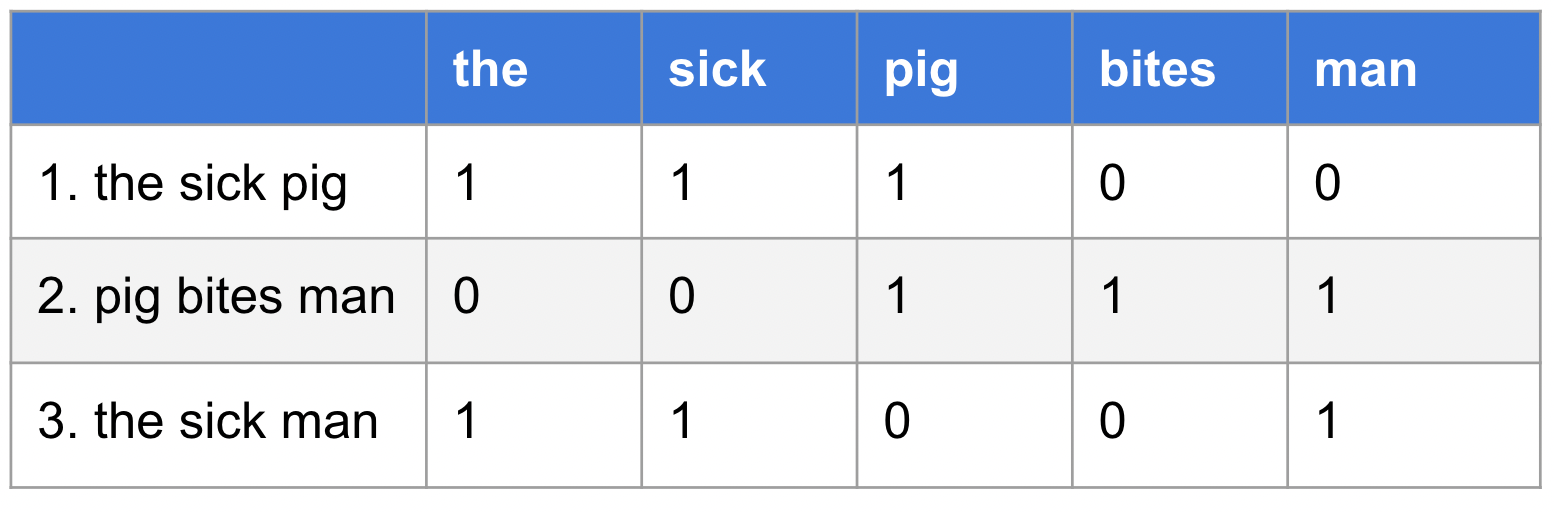
The Bag-of-Words technique for converting documents to feature matrices can be easily transformed into a bag-of-procedures technique for vectorizing claims.
Bag-of-words can be leveraged to train simple, baseline models. However, to achieve high-caliber performance, more sophisticated vectorization methods are required. In text analysis, word embedding usage can frequently outperform bag-of-words. Embeddings are vectors, a few hundred dimensions in length, which capture the relationships between words. Consider for example, the words “cat” and “feline”. These words are very similar in their meaning, but bag-of-words still treats them as two completely different entities. Meanwhile, their embeddings will contain a high degree of overlap, which can provide more nuance during model training. Basically, the embeddings for “feline” and “cat” can be thought of as two coordinate points that are proximate to each other in a high-dimensional word-space. Words within that embedding space have sophisticated geometric relationships that can help with model training. For example, if we take vector embedding representing “King”, subsequently subtract the vector “Man”, and finally add the vector “Woman”, then we will obtain the vector for “Queen”. Such subtle representation of semantic relationships in text can lead to better modeling.
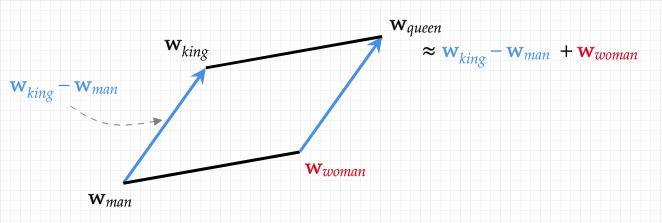
Embeddings for “King”, “Queen”, “Man”, “Woman” form a parallelogram in high dimensional space. Feeding these relationships into model training leads to improved performance. Source
Multiple existing tools can compute embeddings from document texts. These tools are designed to run at enormous scale, since millions of documents are usually required to generate meaningful embeddings. The general computation strategy is to calculate the co-occurrence counts between proximate words in individual sentences across the millions of documents. This yields an unwieldy matrix containing tens of thousands of columns that correspond to the corpus vocabulary. Fortunately, these columns can be dimensionally reduced using a single-layer neural network. Reducing each matrix row to a 300-dimensional vector produces the embedding of the word that’s represented by the row. This operation is straightforward to parallelize in an analytics engine such as PySpark.
If we apply PySpark’s built-in embedding generator to hundreds of millions of claims, then we can project all procedure codes into a high dimensional embeddings space. Proximity within that space will be determined by procedure similarity. For instance, two surgical procedures will have greater vector similarity in comparison to two unrelated procedures such as a blood-test and a CT scan screening. Integrating this measure of proximity into the model training could yield improved denial prediction results.
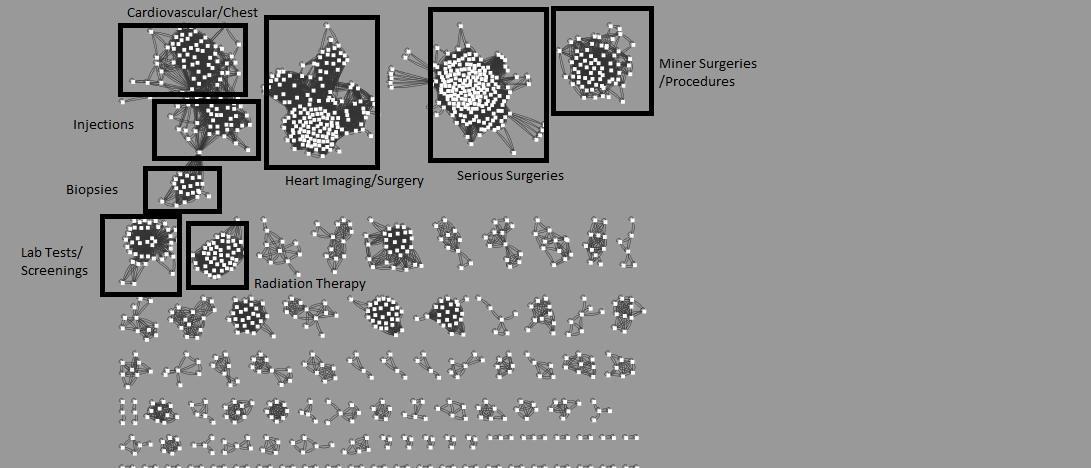
Procedure embeddings clustered by vector similarity. Similar procedures fall into similar special clusters.
Furthermore, due to the unique structure of medical codes, there are additional steps that we can take to make our embeddings more informative. All medical codes exist within manually structured hierarchical ontology that’s maintained and updated by medical experts. For example, surgery procedures exist with a single branch of the hierarchy, that’s further subdivided into stomach surgeries, heart surgeries, etc. Meanwhile all imaging procedures are present in a completely different hierarchy branch. Can we somehow encode this hierarchical information into our embedding similarities? Yes, though the solution is not so simple.
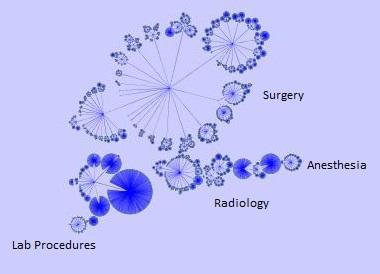
An ontological tree representation of procedure codes organized by medical category.
Hierarchical trees take up a lot of space within standard Euclidean geometry. For the tree leaves to be close together, the higher branching points must be further apart. For example, if we place all stomach surgery codes next to each other in Euclidean space, and we also position the heart surgery codes together in such a manner that the edges of the tree don’t overlap, then we’ll be forced to place the two surgical branches far apart due to lack of space. Standard Euclidian embeddings are simply unable to maintain both contextual similarity and hierarchical similarity. So what should we do?
One elegant solution is to switch from Euclidean space to hyperbolic space. A hyperbola is a type of curve that resembles a funnel, when visualized in 3-dimensions. The edges of the funnel shoot-off into infinity. Thus, the inner surface of the funnel offers us infinite space for storing the hierarchy. By projecting our embeddings onto a hyperbolic surface, we can store both hierarchical information and co-occurrence information.
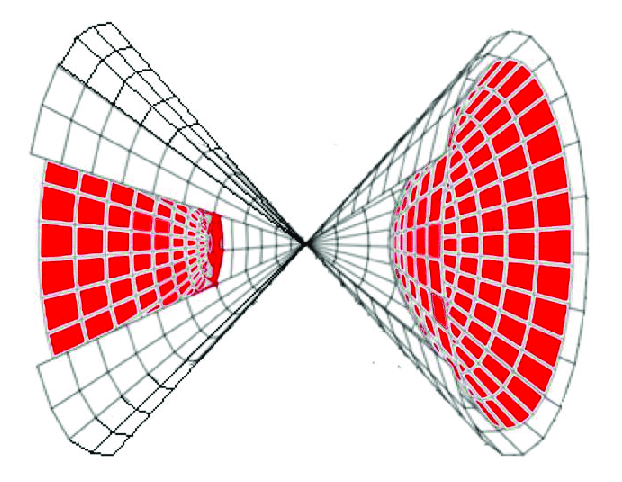
The funnel-shaped inner surface of a 3-dimensional hyperbolic curve contains plenty of space to support an expanding hierarchy as the curve also expands into infinity. Source
A research lab at Facebook has shown how to compute such hyperbolic embeddings (also known as Poincaré embeddings) on a high-dimensional hyperbolic surface. These embeddings were obtained for all English nouns in a manner that preserved both symmetric similarity and categorical noun hierarchies (such as animal --> reptile --> turtle --> sea turtle). Of course, beyond NLP, this technique has broad applicability to procedure and diagnosis code analysis.
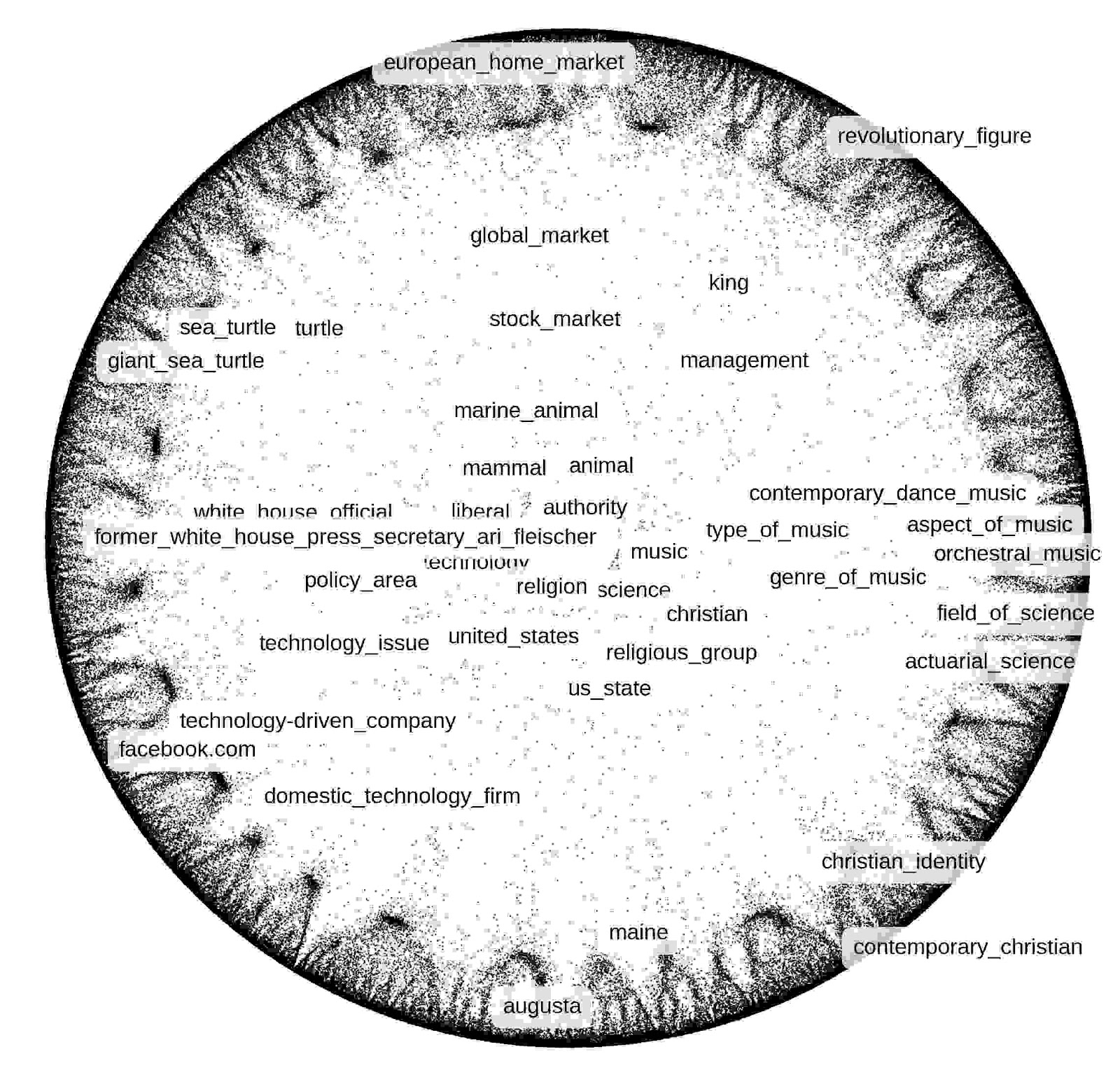
Hierarchical noun embeddings that have been projected onto the 2D surface of a hyperbolic curve. These embeddings maintain the ontological structure of the hierarchy. Source
Ideas from NLP are very relevant when it comes transforming raw claims into features, for modeling purposes. However, the techniques that we’ve presented are only applicable to those portions of a claim that are associated with procedures and diagnoses codes. Beyond these codes, additional claim data must also be fed into the model. This data includes procedure billed amount, procedure date, drug dosage (where applicable), the patient’s age, the physician’s specialty and address, the name of the insurance company, and additional metadata describing in more the detail certain billed procedures (such as for instance whether shoulder surgery was applied to the left or right shoulder). The introduction of such heterogeneous features requires an appropriate choice of training model. We will discuss the challenges associated with denial prediction model selection and training in a future series of blog posts.